Recurrent Neural Networks: Unveiling Sequential Power
In the realm of deep learning, vanilla feed-forward neural networks fall short when dealing with sequential data. Sequential information can be best illustrated by text. The context of each word in a sentence is semantically dependent on the words that came before it. Preserving and retaining this information is a short-coming of a typical feed-forward neural net.
RNNs, on the other hand, allow us to remember and use previous inputs for future predictions. To understand how, let us dive into the architecture and inner workings of these networks.
The Architecture
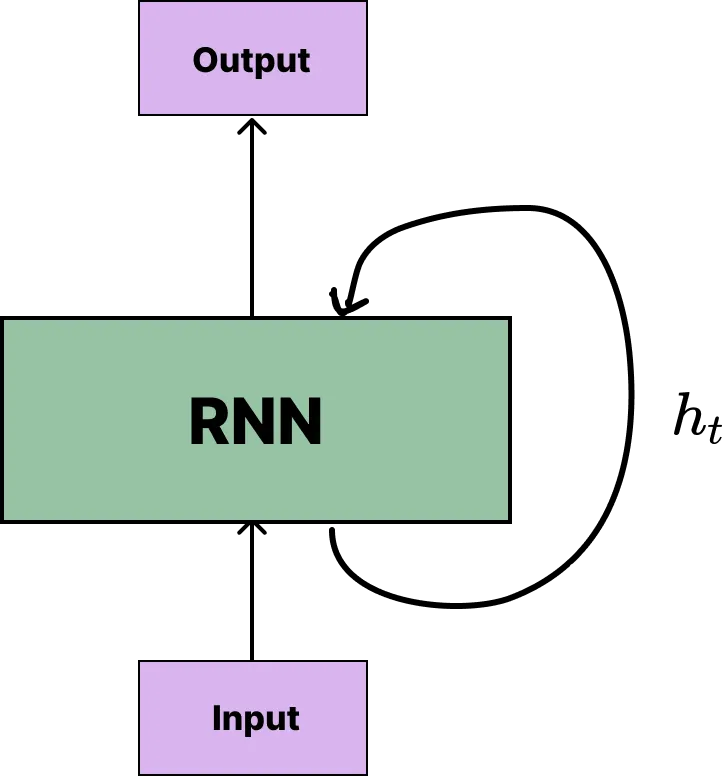
An extremely simple model of the RNN architecture
From an eagle’s eye view of RNNs, we can begin to form some intuition in regard to how a temporal characteristic is introduced to sequential data.
We can think of the recurrence shown with h as an unrolling through time. Each step carries information from previous steps to make predictions on the current input. Hence, as the network processes each input from the input vector, h evolves. This evolution is the driving factor in every RNN and also the key insight as to how RNNs preserve temporal attributes.
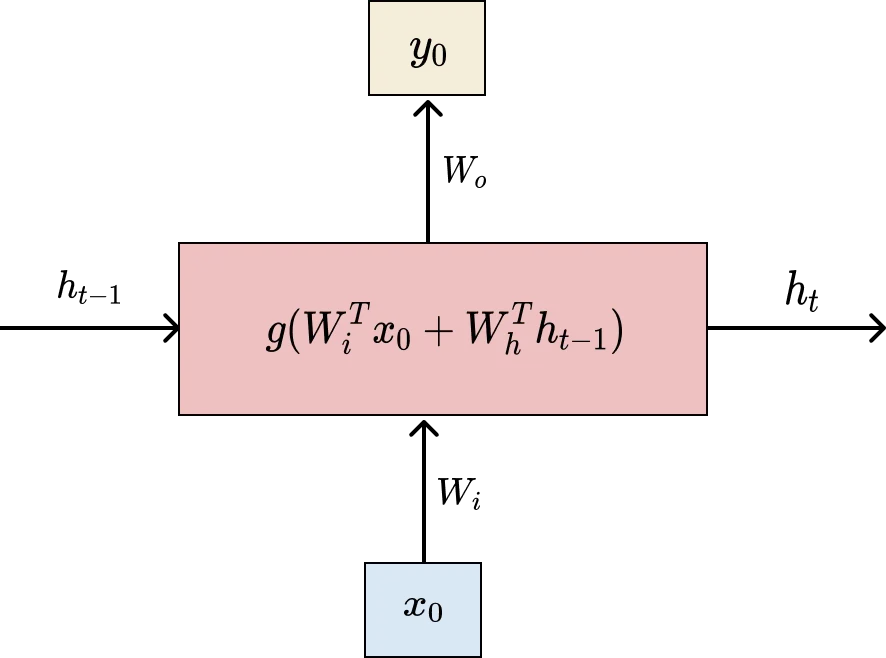
The diagram above is a visual unrolling of the recurrence shown in the eagle’s eye perspective. Note that g is the activation function that provides non-linearity in our neural network. Usually, for RNNs, the most common activation function is the tanh function.
- h is the hidden state
- x is the input vector
- y is the output vector
Weight matrices are also assigned for the inputs, hidden states, and outputs at every layer. These weight matrices are represented as W with subscripts i, h, and o (respectively).
Note that these weights only need to be initialized once.